|
Mengzhen Liu I am a graduate student at the School of Computer Science, Peking University, advised by Prof. Shanghang Zhang. My research focuses on Vision-Language-Action models, Embodied Agents, and Robotic Manipulation, especially active perception, spatial-temporal reasoning, and efficient multimodal systems for real-world robotics. I am always open to academic and industrial collaborations around VLA models, robot learning, and embodied intelligence. Email / Google Scholar / OpenReview / GitHub |

|
News
|
|
Research
My work studies generalist robotic agents that can perceive, reason, and act in complex scenes. Recent projects span end-to-end VLA frameworks, active view selection, multi-embodiment robot data, dexterous manipulation, human-to-robot motion transfer, and training-free acceleration for multimodal models. |
| Selected Publications (*, †, ‡ indicate equal contribution, corresponding author, and project leader where applicable.) Rows with Mengzhen Liu as an equal-contribution first author are highlighted. |

|
SaPaVe: Towards Active Perception and Manipulation in Vision-Language-Action Models for Robotics
Mengzhen Liu *, Enshen Zhou *‡, Cheng Chi, Yi Han, Shanyu Rong, Liming Chen, Pengwei Wang, Zhongyuan Wang, Shanghang Zhang† [Paper] / [Project] / [BibTeX]Copy Success! TL;DR: End-to-end active perception and active-view manipulation for VLA robots. CVPR 2026, Highlight |
|
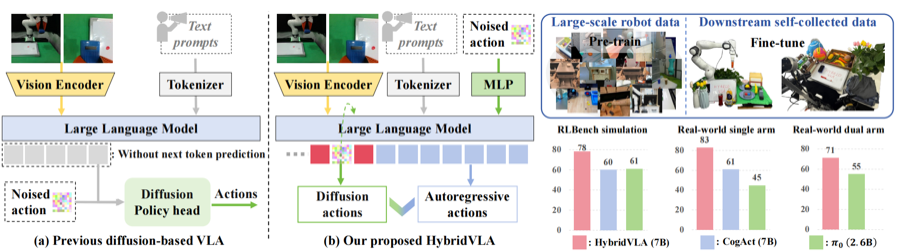
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Jiaming Liu, Hao Chen *, Pengju An, Zhuoyang Liu *, Renrui Zhang‡, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, Chengkai Hou, Mengdi Zhao, Kaichen Zhou, Pheng-Ann Heng, Shanghang Zhang† [Paper] / [Project] / [Code] / [BibTeX]Copy Success! TL;DR: A unified VLA model that combines diffusion and autoregressive action generation. ICLR 2026 |
|
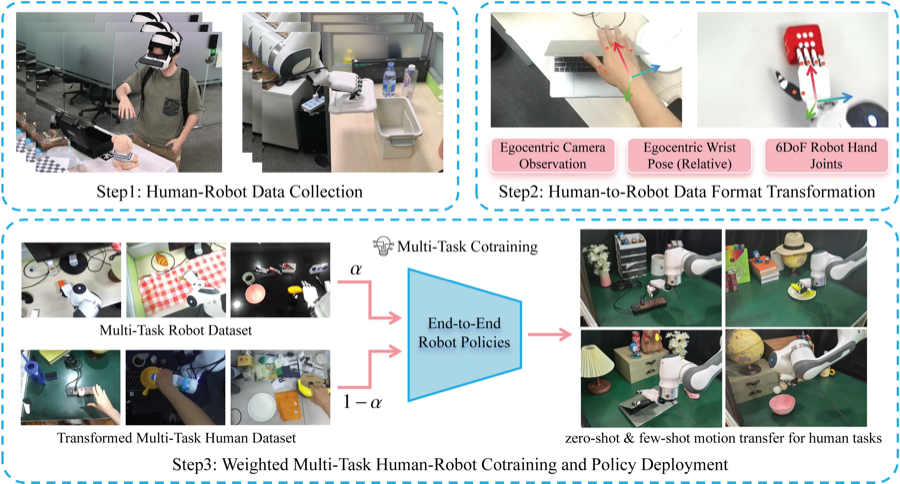
MotionTrans: Human VR Data Enable Motion-Level Learning for Robotic Manipulation Policies
Chengbo Yuan, Rui Zhou *, Mengzhen Liu *, Yingdong Hu, Shengjie Wang, Li Yi, Chuan Wen, Shanghang Zhang, Yang Gao† [Paper] / [Project] / [ICRA] / [BibTeX]Copy Success! TL;DR: Learning robot manipulation policies from human VR motion data. ICRA 2026 |
|
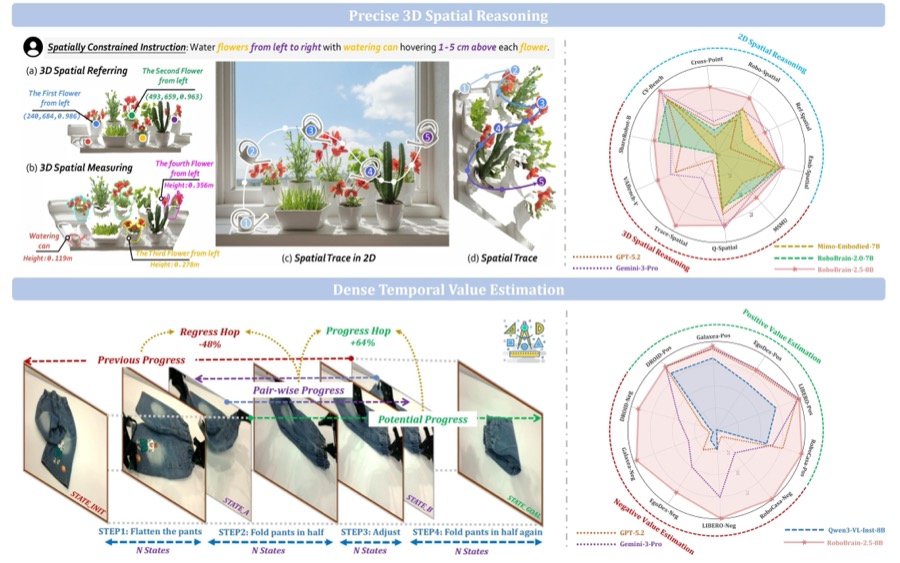
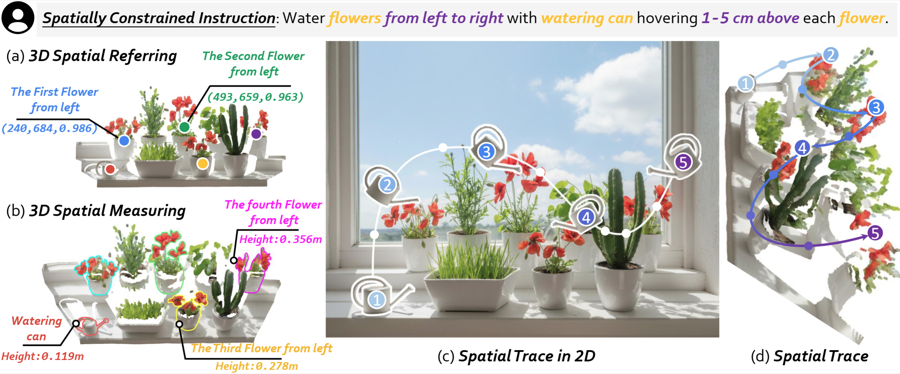
RoboBrain 2.5: Depth in Sight, Time in Mind
BAAI RoboBrain Team (including Mengzhen Liu) [Paper] / [Project] / [Code] / [BibTeX]Copy Success! TL;DR: Embodied foundation model with stronger depth and temporal understanding. Technical Report 2026 |
|
RoboTracer: Mastering Spatial Trace with Reasoning in Vision-Language Models for Robotics
Enshen Zhou *, Cheng Chi *, Yibo Li, Jingkun An, Jiayuan Zhang, Shanyu Rong, Yi Han, Yuheng Ji, Mengzhen Liu, Pengwei Wang, Zhongyuan Wang, Lu Sheng†, Shanghang Zhang† [Paper] / [Project] / [Code] / [BibTeX]Copy Success! TL;DR: Metric-grounded spatial trace reasoning for robotics. arXiv 2025 |
|
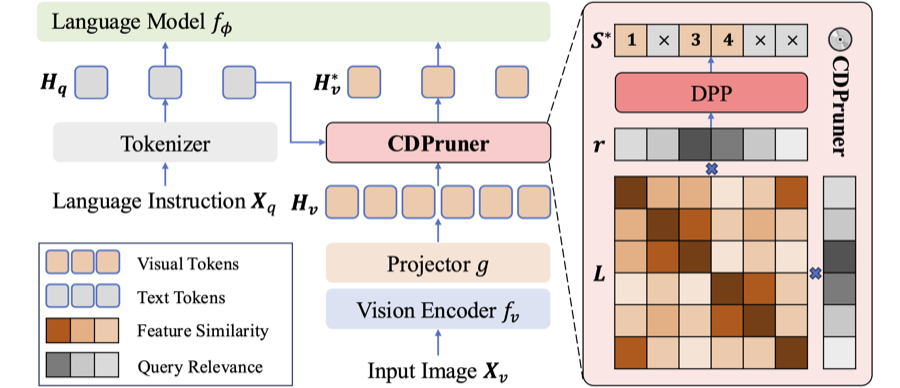
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs
Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu‡, Yuan Zhang, Junwen Pan, Qi She‡, Shanghang Zhang† [Paper] / [Code] / [BibTeX]Copy Success! TL;DR: Training-free token pruning via conditional diversity for efficient MLLMs. NeurIPS 2025 |

|
CordViP: Correspondence-based Visuomotor Policy for Dexterous Manipulation in Real-World
Yankai Fu, Qiuxuan Feng, Ning Chen, Zichen Zhou, Mengzhen Liu, Mingdong Wu, Tianxing Chen, Shanyu Rong, Jiaming Liu, Hao Dong, Shanghang Zhang† [Paper] / [Project] / [RSS] / [BibTeX]Copy Success! TL;DR: Correspondence-aware visuomotor policy for real-world dexterous manipulation. RSS 2025 |

|
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
RoboMIND Team: Kun Wu *, Chengkai Hou *, Jiaming Liu *, Zhengping Che *, Xiaozhu Ju *, ..., Mengzhen Liu, ..., Shanghang Zhang, Jian Tang [Paper] / [Project] / [BibTeX]Copy Success! TL;DR: Large-scale multi-embodiment robot manipulation data and benchmark. RSS 2025 |
|
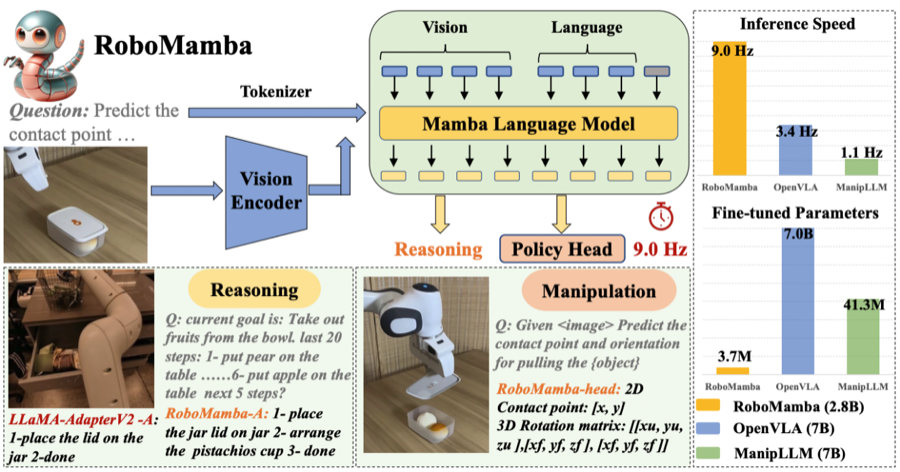
RoboMamba: Efficient Vision-Language-Action Model for Robotic Reasoning and Manipulation
Jiaming Liu *, Mengzhen Liu *, Zhenyu Wang, Pengju An, Xiaoqi Li, Kaichen Zhou, Senqiao Yang, Renrui Zhang, Yandong Guo, Shanghang Zhang† [Paper] / [Project] / [Code] / [BibTeX]Copy Success! TL;DR: Efficient VLA reasoning and manipulation with Mamba. NeurIPS 2024 |
|
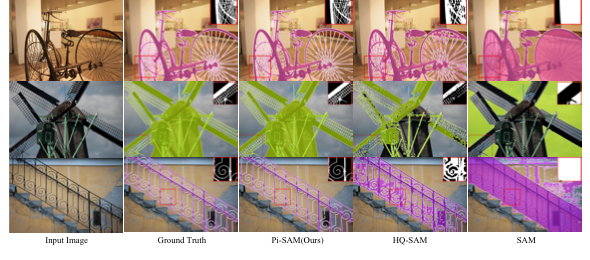
Segment Anything with Precise Interaction
Mengzhen Liu, Mengyu Wang, Henghui Ding, Yilong Xu, Yao Zhao, Yunchao Wei [Paper] / [BibTeX]Copy Success! TL;DR: High-precision and interaction-friendly adaptation of SAM. ACM MM 2024, Oral |
| Education |
|
|
Peking University
2025 - present Graduate Student, School of Computer Science Advisor: Prof. Shanghang Zhang |
|
|
Beijing Jiaotong University
2021 - 2024 B.Eng. in Computer and Information Technology GPA ranking: 1 |